Description
At GitHub, we draw on our own experience using GitHub to build GitHub. As an example of this, we use a number of GitHub Advanced Security features internally. This post covers how we rolled out Dependabot internally to keep GitHub’s dependencies up to date. The rollout was managed by our Product Security Engineering Team who work with engineers throughout the entire development lifecycle to ensure that they’re confident in shipping new features and products. We’ll cover some background about how GitHub’s internal security teams think about security tooling in general, how we approached the Dependabot rollout, and how we integrated Dependabot into our existing engineering and security processes.
Keeping our dependencies up to date is one of the easiest ways to
keep GitHub’s systems secure. The issue of supply chain security has
become increasingly obvious in the past number of years, from the
malicious flatmap-stream package, to the most recent log4shell vulnerabilities. Dependabot
will alert developers when a repository is using a software dependency
with a known vulnerability. By rolling out Dependabot internally to all
of our repositories, we can measure, and significantly reduce, our usage
of software dependencies with known vulnerabilities.
How we approach new tools and processes
Within Product Security Engineering, we spend a lot of time thinking about how new security tools and processes may impact the day-to-day work of our engineers. We use a number of guiding principles when evaluating tools and designing a rollout plan. For example, Does the security benefit of this new process outweigh the impact on engineering teams? How do we roll this out incrementally and gather feedback? What are our expectations for engineers, and how do we clearly communicate these expectations?
For Dependabot in particular, some of these questions were easy to answer. Dependabot is a native feature of GitHub, meaning, that it integrates with our engineers’ current workflows on GitHub.com. By better tracking the security of our software supply chain, we will keep GitHub and our users secure, which outweighs any potential impact on engineering teams.
We used a three-stage process to roll out Dependabot at GitHub: measure the current state of Dependabot alerts, a staged rollout to enable Dependabot incrementally over the organization, and finally, focus on remediating repositories with open Dependabot alerts.
Measurement
Our first aim was to accurately measure the current state of dependencies internally. We were not yet concerned with the state of any particular repository, but wanted to understand the general risk across the company. We did this by building internal tools to gather statistics about Dependabot alerts across the whole organization via the public GraphQL API. Getting this tooling in place early allowed us to gather metrics continuously and understand the general trends within GitHub before, during, and after the rollout.
Dependabot, like other GitHub Advanced Security features, can be enabled for all repositories within an organization from the organization’s administration page. However, GitHub has several thousand repositories internally, and we were aware that enabling Dependabot organization-wide could have a large impact on teams. We mitigated this impact in two ways: a staged rollout and frequent company-wide communications.
Rollout
A staged rollout allowed us to gather feedback from an initial set of repository owners before proceeding with the organization-wide rollout. We use this approach internally for security tools within GitHub, as we believe that unshipping a new tool or process can cause even more confusion across the company. For Dependabot, we decided on enabling the feature initially on a subset of our most active repositories to ensure that we could gather useful feedback. We then expanded it to a larger subset, before finally enabling the feature organization wide.
As a heavily-distributed company working asynchronously across multiple timezones, we used a mixture of GitHub Issues and GitHub Discussions to share new tools and processes with engineers. We aimed to answer, clearly and succinctly, the most important questions in our communications: What are we doing? Why are we doing this? When are we doing this? Lastly, what do I need to do? The last question was key. We made it clear that we were rolling out Dependabot organization-wide to understand our current risk and that, while we encourage repository owners to upgrade dependencies, we were not expecting every Dependabot alert to be fixed right away.
We also used these discussions as a touchpoint for other related tasks, such as encouraging teams to archive repositories if they are no longer in use. In organizations, there are always early adopters of new tools and features. Although we clearly laid out our incremental rollout plan, we also encouraged teams to enable Dependabot right away if it made sense for their repositories.
All in all, we made the initial ship to 200 repositories, followed up in 30 days with another 1,000 repositories, and enabled it organization-wide at the 45-day point from our initial ship. After enabling it organization-wide, we also used the "Automatically enabled for new repositories" feature to ensure that new repositories are following best practices by default.
Remediation
Once we had Dependabot enabled for all GitHub repositories, we could measure the general trend of Dependabot alerts across the company. Using our tooling, we could see that the general trend of Dependabot alerts across the company was broadly flat. We now switched our focus from measuring the current state to working with repository owners to upgrade our dependencies.
We managed this process through GitHub’s internal Service Catalog tool. This is the single source of truth within GitHub for services running inside GitHub and defines where a service is deployed, who owns the service, and how to contact them. The s_ervice_ concept is an abstraction over repositories. The Service Catalog only tracks repositories that are currently deployed inside GitHub, which is a small subset of repositories. By leveraging the Service Catalog, we could ensure that we focused our remediation efforts on repositories that are running in production, where a vulnerable dependency could present a risk to GitHub and our users.
Each service can have domain-specific metrics associated with them, and we built tooling to continuously pull Dependabot data via the GitHub REST API and upload it to the Service Catalog:
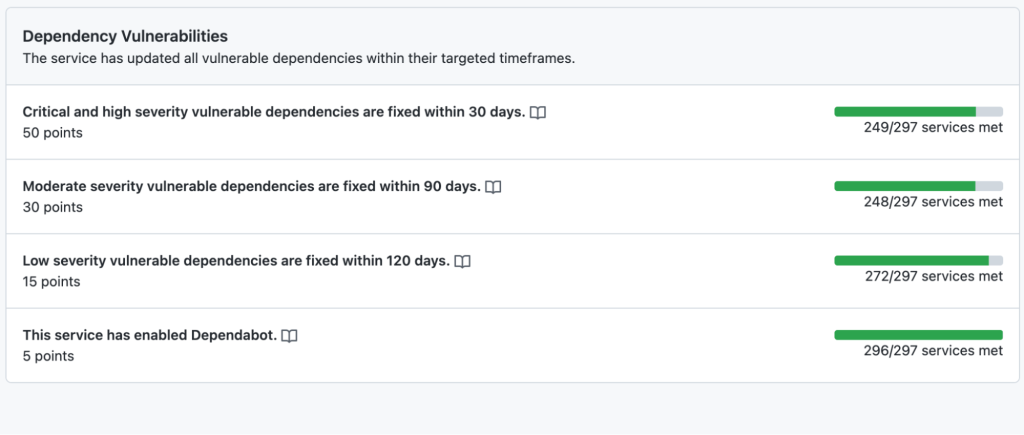
The Service Catalog allows us to assign service level objectives (SLOs) to individual metrics. We acknowledge that not all Dependabot alerts can be actioned immediately. Instead, we assign a realistic grace period for service owners to remediate Dependabot alerts before marking a metric as failing.
At this point, the Service Catalog metrics showed that around one-third of services had Dependabot alerts that needed remediation. We then needed a process for prioritizing and managing the work of upgrading dependencies across the company. We decided to integrate with GitHub’s internal Engineering Fundamentals program. This takes a company-wide view of the various metrics in the Service Catalog that we consider the baseline for well-maintained, available, and secure services.
The program is all about prioritization: given the current set of services not meeting baseline expectations, what is the priority for service owners right now? By integrating Dependabot alerts into the program, it allows us to clearly communicate the priority of dependency upgrades against other foundational work. This also drove conversations around deprecation. Like all companies, we had a number of internal services that were currently, or soon to be, deprecated. By making these metrics clearly visible, it allowed us to quantify the risk of keeping these deprecated services running in production and led to service owners reprioritizing the work to fully shut down those services.
The cornerstone of GitHub’s Engineering Fundamentals program is a monthly synchronous meeting with engineering leadership and service owners. Every month, we define realistic goals for service owners to achieve in the next four weeks then review the progress against those goals. This allowed us to break down the nebulous task—fixing all open Dependabot alerts—into a clear set of tasks over a series of months. After integrating the Dependabot metrics with the program, we then made it a focus for engineering teams for a whole quarter of the year, which allowed us to build momentum on upgrading dependencies for services.
Outcomes
Our focus on Dependabot alerts was a success. By leveraging the Engineering Fundamentals program, we increased the percentage of services with zero Dependabot alerts from 68% up to 81%. This represents roughly 50 core GitHub services remediated in just three months, including several services performing large Rails upgrades to ensure they are using the most recent version. As the Engineering Fundamentals program runs continuously, this was not a one-off piece of work. Rather, the program allows us to follow the Dependabot alert metrics over time and intervene if we see them trending in the wrong direction.
After trialing this approach with Dependabot, we have since incorporated other GitHub Advanced Security tools and features, such as CodeQL into our Engineering Fundamentals program. By integrating more sources of security alerts, GitHub now has a more complete picture of the state of services across the company, which allows us to clearly prioritize work.
As an internal security team, GitHub’s Product Security Engineering Team faces many of the same challenges as our GitHub Enterprise users, and we use our experience to inform the design of GitHub features. Our emphasis on organization-wide metrics was a key part of measuring progress on this piece of work. That feedback has informed how we designed the Security Overview feature, which allows GitHub Enterprise users to easily see the current state of GitHub Advanced Security alerts across their organization.
Are you inspired to work at GitHub?
- Dedicated remote-first company with flexible hours
- Building great products used by tens of millions of people and companies around the world
- Committed to nurturing a diverse and inclusive workplace
- And so much more!